不管是IG還是FB,都可以看到網路上有免費的留言抽獎神器,
但是不知道為什麼都沒看過Google Map評論抽獎器(還是只有我沒看過?)
本篇會將指定店家的Google評論全部爬下來,並指定給五星評價的人才有抽獎資格~
如果有想指定評論時間的也可以設定條件喔~
使用環境
行前說明
在抽獎前我要推薦一下內湖站超好吃的餐廳-極餓便當專門店,因為實在太好吃,
所以這篇就用極餓便當專門店舉例喔~
程式碼
import requests
import json
import random
j = 0
lottery_pool = []
while 1:
# 這邊的連結不是Google Map商家的連結喔!我們明天再說這個連結是怎麼來的~
url = "https://www.google.com.tw/maps/preview/review/listentitiesreviews?authuser=0&hl=zh-TW&gl=tw&pb=!1m2!1y3765762734390772041!2y17055821615375049737!2m2!1i"+ str(j) +"!2i10!3e1!4m5!3b1!4b1!5b1!6b1!7b1!5m2!1siMZEYbemFIeymAWI2pko!7e81"
j = j + 10 # 因為一頁評論最多有十條,連結規律是10、20、30...,所以一次要加10
text = requests.get(url).text # 發送get請求 (這邊我是看zino lin大神的教學)
pretext = ')]}\'' # 取代特殊字元
text = text.replace(pretext,' ') # 把字串讀取成json
soup = json.loads(text) # 載入json檔
review_list = soup[2] # 留言的位置
if review_list is None:
break
for i in review_list:
print("正在抽獎...")
# 姓名: str(i[0][1])
# 時間: str(i[1])
# 星星數: str(i[4])
# 留言內容: str(i[3])
if i[4]==5 and i[3] != None: # 給五星加有留言的評價才可以抽獎喔
dict = [str(i[0][1]),str(i[1]),str(i[4]),str(i[3])]
lottery_pool.append(dict)
winner_index = random.sample(range(0, len(lottery_pool)-1), 3) # 設定抽3人
print("-------中獎名單------")
for i in winner_index:
print(lottery_pool[i])
成果發表會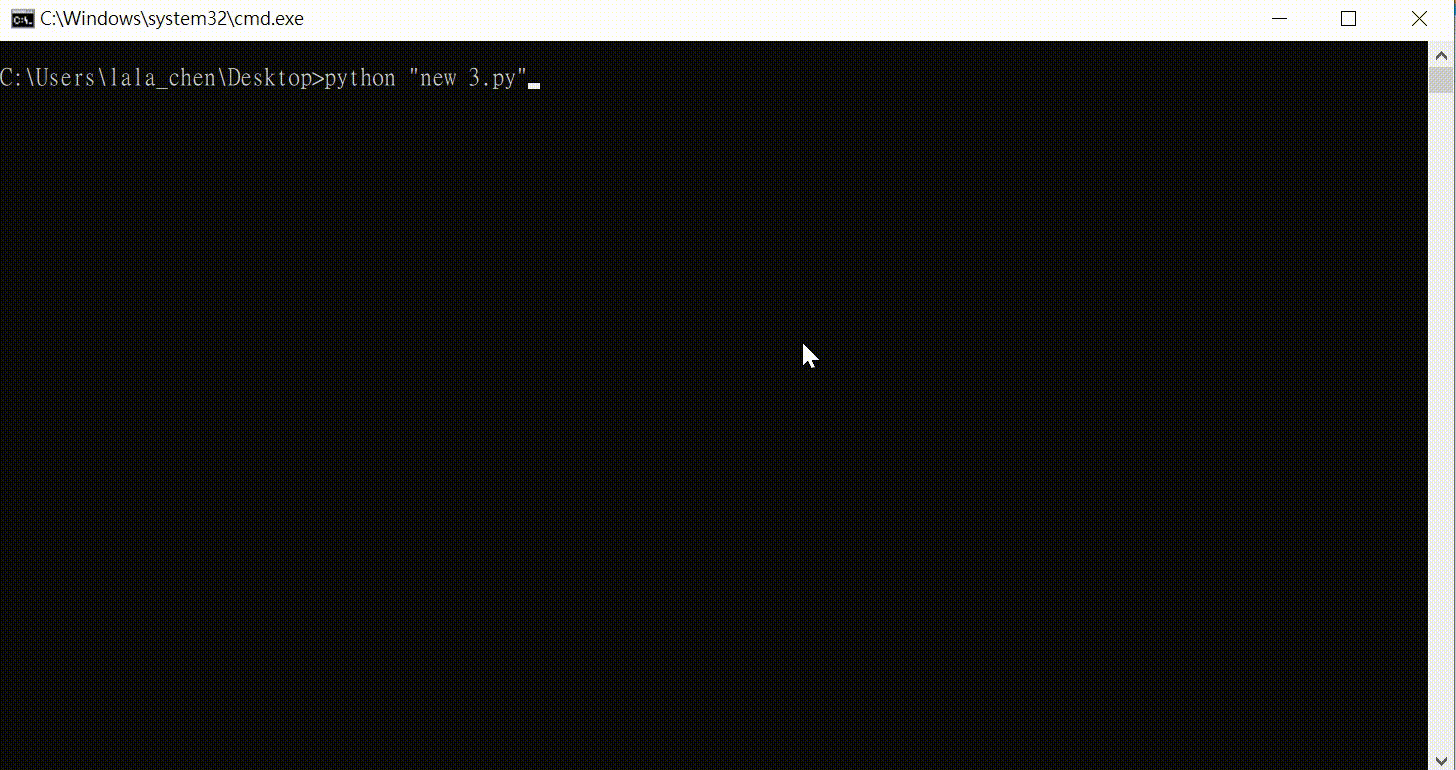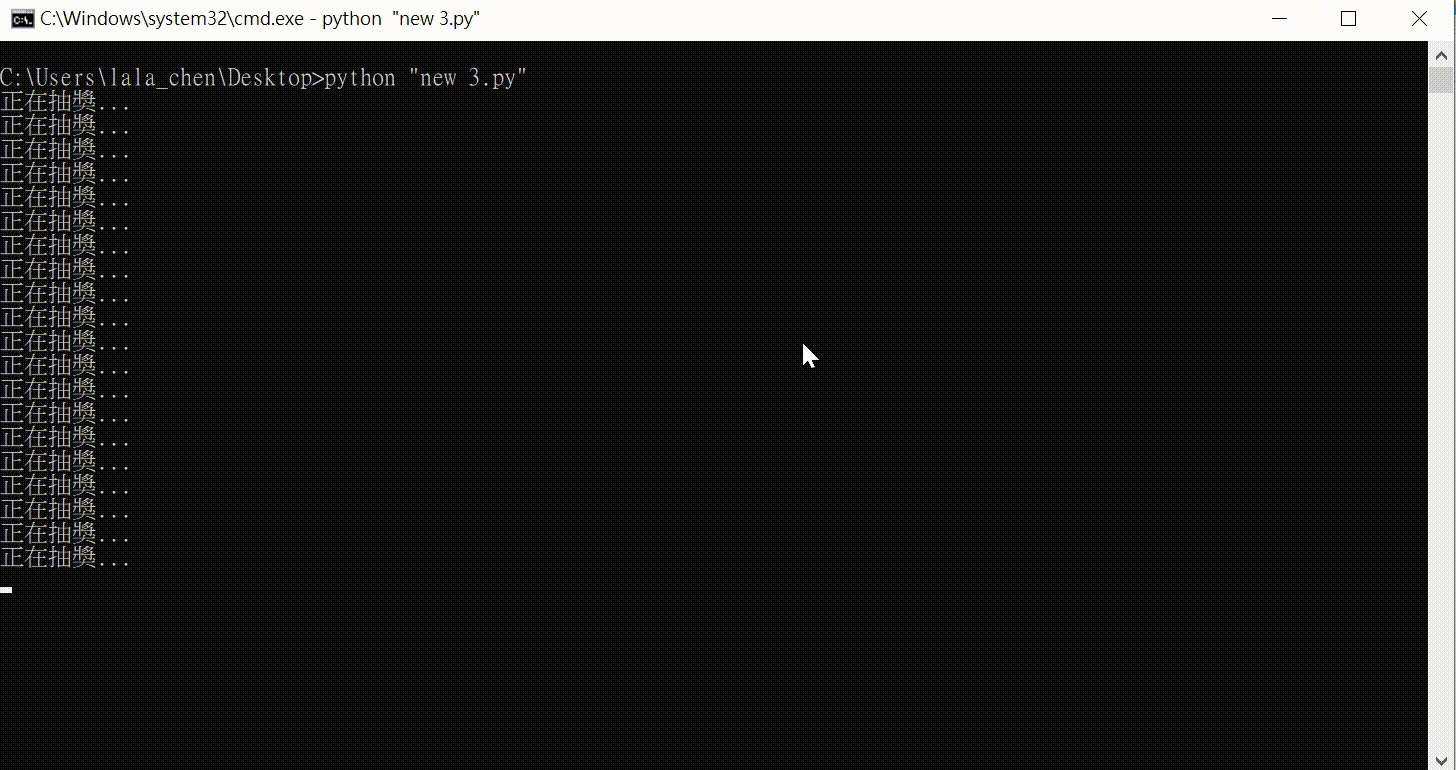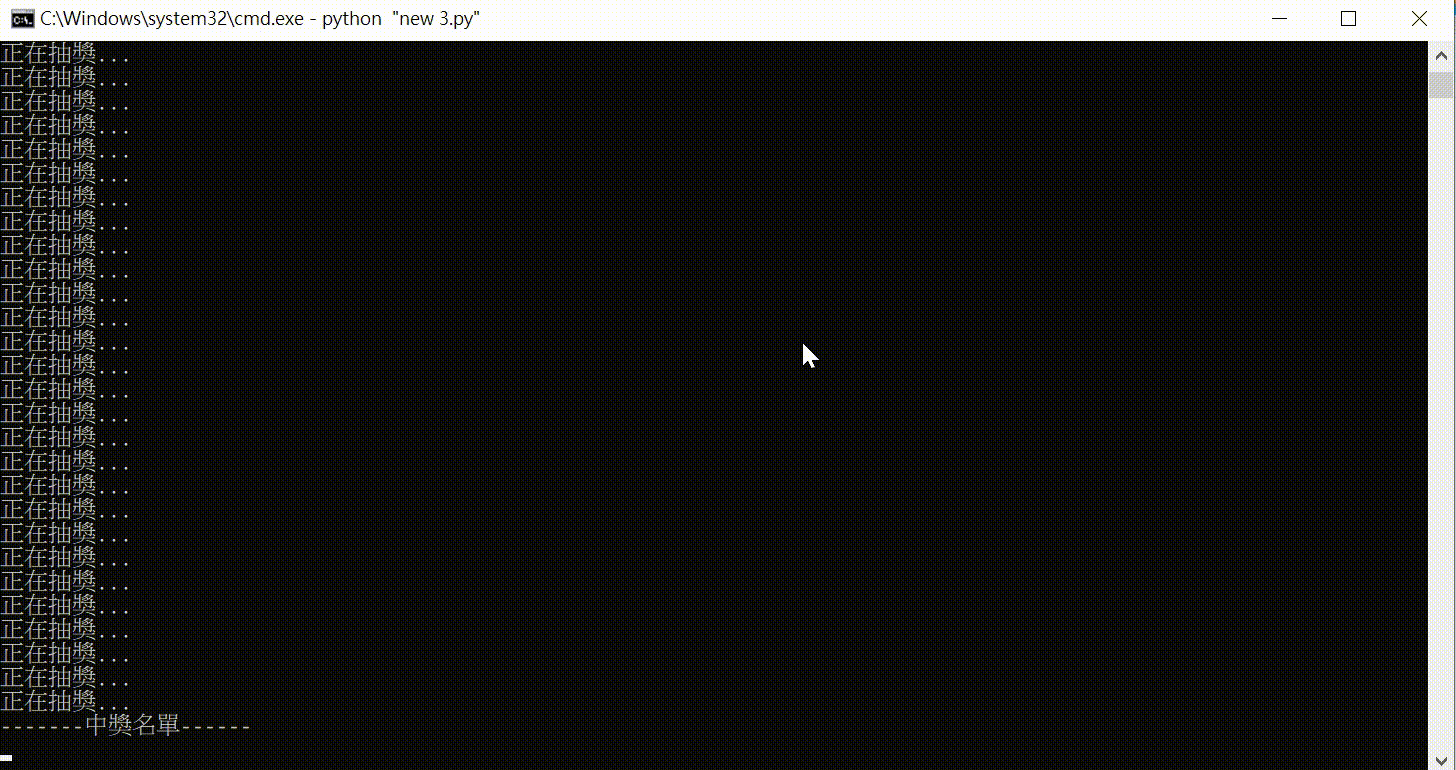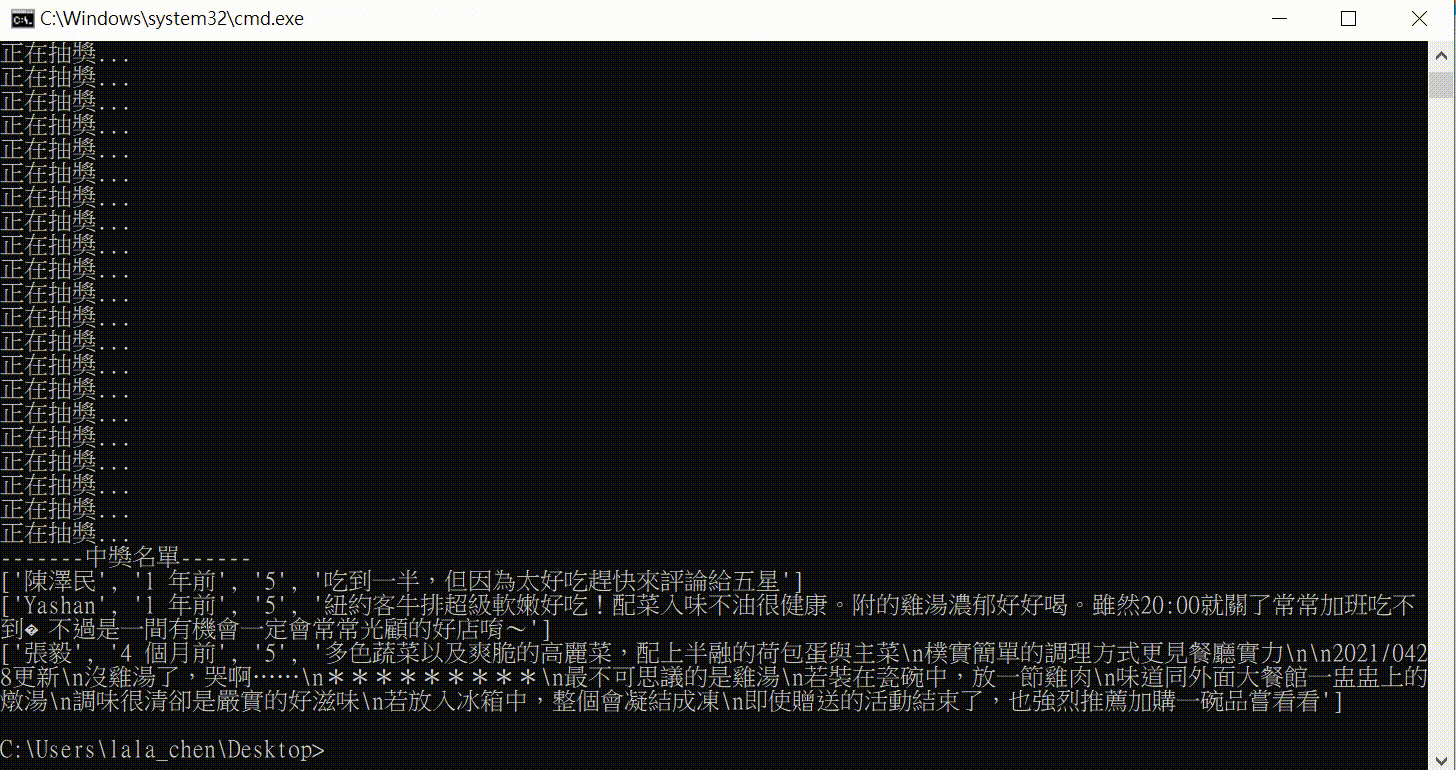
沒錯! 這間便當就是這麼好吃!
溫馨小提醒
程式中的url連結不是Google Map店家的連結喔!
明天再跟大家解釋詳細的抓評論方法~
我在執行程式大概到第30次左右的時候會出現這個錯誤訊息:
File "C:\Users\User\Downloads\google.py", line 24, in <module>
soup = json.loads(text)
File "C:\Users\User\lib\json\__init__.py", line 346, in loads
return _default_decoder.decode(s)
File "C:\Users\User\lib\json\decoder.py", line 337, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "C:\Users\User\lib\json\decoder.py", line 355, in raw_decode
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
如果不是一開始編譯就出現這個錯誤,而是執行數次後突然發生,
那就是對方網站發現你在爬蟲把你擋掉了!
這時候除了換連一個網路這種治標不治本的方法外,還可以用fake_useragent套件將我們爬蟲請求的身分偽裝成某個瀏覽器,詳細步驟如下:
pip install fake_useragent
from fake_useragent import UserAgent
ua = UserAgent() # 產生一個 user agent
user_agent = ua.random # 隨機產生一個 user agent字串
headers = {'user-agent': user_agent}
text = requests.get(url, headers=headers).text
這樣執行好幾次就不會再出現上面的錯誤訊息囉~
但是還是建議加個time.sleep()讓程式休息一下,畢竟爬蟲會消耗對方伺服器資源,我們要有禮貌 ^-^
網路上查了一下 那個錯誤大多發生在json格式不正確的時候
你可以印出text看看 是不是有多或少,、[、{這類的符號
我也覺得超奇怪 想說明明評論沒有變 怎麼突然出錯了XD
你說的 Error 我猜是被檢測為網路爬蟲了,問題不在 soup = json.loads(text) 這行。
實際我多次執行測試後,請求回傳狀態碼為 429 (Too Many Requests),將回傳的資料儲存下來(也就是你的 text),發現是個 reCAPTCHA (我不是機器人)的驗證網頁,其實就是你太頻繁地對它送出請求啦(requests.get(url))。
(IP 被擋,所以你換個網路就恢復正常)
遇到這種狀況可以查詢"反爬蟲"關鍵字,常見的方法就是請求之間加入延遲、請求加上 User-Agent 等等,給你參考。
感謝您!! 我後來有發現它跳出一個確認不是機器人的網頁 但是點確認後還是不能執行 所以我就換網路了
我再去查查怎麼加上User-Agent,謝謝您~

